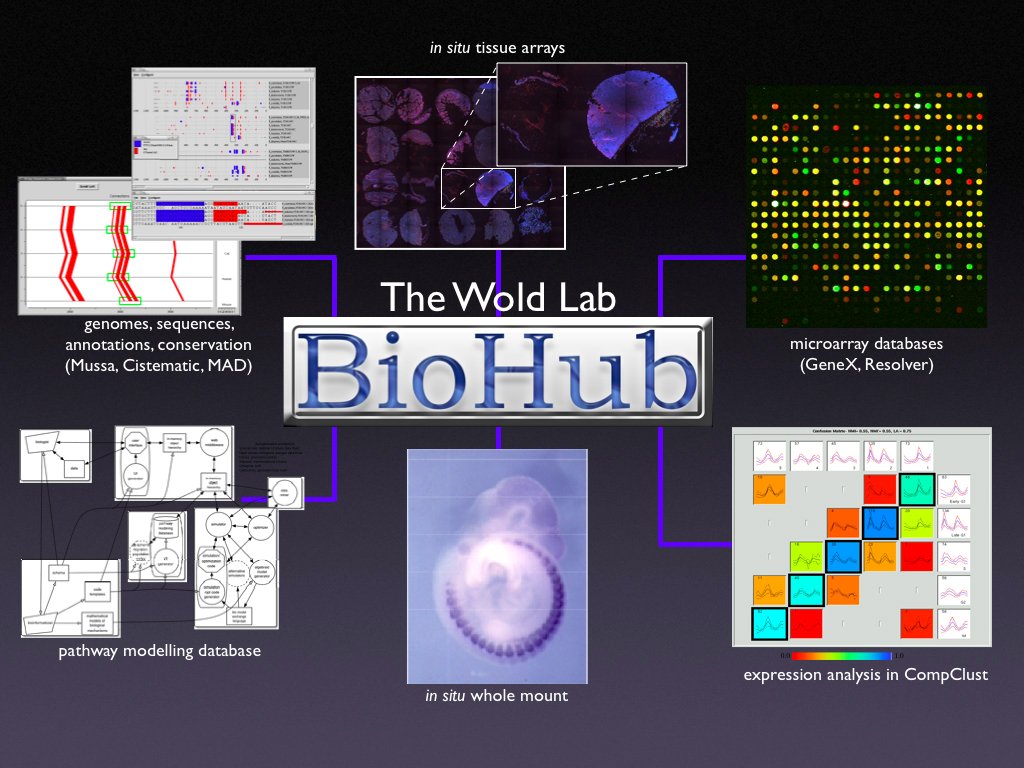
The Caltech BioHub: Unified access to diverse bioinformatics datasets
The number and diversity of bioinformatics data sources, as well as their
ever-increasing sizes, pose numerous challenges to investigators wanting
to perform integrative data analyses in their research. The need to
combine myriad data sources, formats and qualities ranging from
well-vetted annotations to mere hypotheses often impedes such efforts.
The BioHub is a relational database and Python API developed at Caltech
that manages associations between numerous genomic-sequence-based and
transcript-based datasets in order to provide centralized query services
and uniform data access. The Biohub was designed to permit biologists to
draw on and combine many disparate data sources for integrative analyses
such as gene network modeling. The central feature in Biohub design is
the Sequence Registry which relates diverse data and annotations to
individual genomic sequence features - usually genes. Key BioHub design
features include:
- Maintains associations between transcript-based results (microarray,
ChIP-array, and in situ expression) and genomic-sequence-based results
(sequence annotations, motif instances, conserved elements)
- Sequence Registry provides unique IDs for a variety of annotations to
build stable associations to peripheral data stores, e.g. Rosetta
Resolver, GeneX, sequence annotation databases, motif databases,
conserved element collections, probe libraries, etc.
- Query entry-points and results are based on common representations
for genes, probes, expression data, motifs and other annotations, all
designed to be integrated and analyzed together, e.g. in the PyMLX
CompClust environment
- Offers a rich collection of sequence operations, e.g. BLAST, BLAT and
regular expression searches, contains/is-contained-in queries, and
neighborhood searches, for any specific (or all) sequence types
- Permits transient, hypothetical annotations to be registered to support
an individual's integrative analyses but hidden from default query
results until they are promoted (or easily removed)
- Automated import of genomes (as assemblies or contigs) including
construction of blast and blat databases
- New genome build releases trigger updates so that transcript and
sequence locations can be tracked across multiple builds
- Supports broad queries, e.g. "For gene X, get me all Mm and Hs
expression data, and all upstream motifs that are conserved in both
species"
The poster presented at PSB 2004 described the status of the current
BioHub prototype, demonstrated the ways it has been used to date
(e.g. in assessing the quality of oligonucleotide probe libraries, for
identifying common regulatory elements, etc.), and described design
plans for future BioHub development.